
NephMadness 2016: Statistics in Nephrology Region

Submit your picks! | For more on NephMadness 2016 | #NephMadness or #StatsRegion on Twitter
Well, I can say with a reasonable degree of confidence that the statistics bracket is shaping up to be a real nail biter. Up is down, black is white, significance is insignificant. In this region new statistical methods go head-to-head against tried and true approaches that have been battle-tested in diverse locales ranging from Atlantic City casinos to the steamy back rooms at Goldman-Sachs. Can one of these contenders take it all the way to the Final Four? There’s always a chance.
Selection Committee member for the Statistics in Nephrology Region:
Perry Wilson, MD MSCE
Dr. Wilson is an assistant professor of medicine at the Yale School of Medicine. His research interests focus on traditional and machine-learning approaches to data in the electronic health record. He is also investigating the use of automated alerting to improve outcomes for patients with acute kidney injury. He is an author of numerous original scientific articles and holds several NIH grants. He also authors a blog, The Methods Man (www.methodsman.com). You can follow @methodsmanmd on Twitter.
Meet the Competitors for the Statistics in Nephrology Region
Bayesian Methods
Frequentist Methods
Pragmatic Trials
Adaptive Trial
Bayesian Methods vs Frequentist Methods
Our first matchup pits all-time favorite Frequentist Methods against the scrappy upstart Bayesian Methods. As you know, Frequentist Methods have dominated the medical literature since Pearson and Neyman came up with the idea of hypothesis testing in 1933. Few of us remember a time before p-values, confidence intervals, and power calculations. But chinks have begun to show in the armor of this one-time Caesar of Causality.
Let’s break down what these methods bring to the table this year in NephMadness.
Bayesian Methods
 What’s the difference between:
What’s the difference between:
This is the probability of my data assuming the drug is ineffective?
and
This is the probability of the drug being ineffective given my data?
It turns out, worlds.
Imagine you are in Vegas playing craps, and you just rolled a hard 10 (that’s two 5s). If you do it again, you’re going to win the whole table a lot of money. And guess what, you do! (Isn’t it fun when we pretend together?) The chances of you rolling two fives again were 1 in 36, giving a p-value of 0.03. You had a 3% chance of doing that feat assuming the dice weren’t rigged. Now, does your rolling two 5s suggest that there is only a 3% chance of the dice being fair? Hell no. This is Vegas—they are VERY serious about their dice. Get it? The p-value is the probability of your data given the null hypothesis, NOT the probability of the null hypothesis given your data.
But it’s the latter that we want. I want to know if the dice are rigged, or if my drug will work, or if my diagnostic test will diagnose correctly.
Well, if you want the probability of the dice being fair given the fact that you just rolled a hard five again, you need Bayes theorem.
Bayes theorem looks like this:
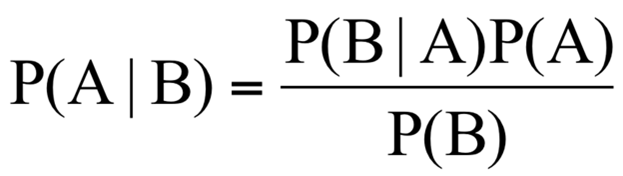
Meaningless gobbledy-gook, but you actually use this all the time in the real world. The idea is that, prior to performing your experiment, you have some “pre-test probability” that the hypothesis you are testing is true. You then perform your experiment, get some data, and modify that pre-test probability to become a post-test probability, which is what we wanted all along.
To use the dice analogy, your pre-test probability that the dice are fair is very high. People get their arms broken for using loaded dice, right? So even after the somewhat low-probability event of two-fives occur, your faith is not shaken too much. Maybe your confidence that the dice were fair went from 99% to 97% sure.
But what if you rolled two fives again?
And again?
And again?
With Bayes theorem, each time the experiment is repeated, we use the new information we’ve learned to modify our probabilities. The post-test probability from experiment 1 becomes the pre-test probability for experiment 2, and so on.
Have you ever ordered a test on a patient, seen the result, and said “I don’t believe it, I’m repeating this test?” Your pre-test probability of the result you saw was simply too low to allow the post-test probability to be high enough to act on. You need more data. You need to feed the Bayesian beast.
But this matchup is far from over. Bayesian methods greatest strength might be its greatest weakness. How do you pick a prior probability, and how can you justify it? Do we really want all of our papers to say: “Given the results of our study, it’s extremely likely that this drug is effective provided that the probability it was effective before we did the study was somewhere above 40%”?
It’s a heated competition. The winner of this matchup might mean the difference between a 95% confidence interval and a 95% credible interval, between a p-value and a likelihood ratio, between robust discussions about prior probability and the status quo.
Frequentist Methods
 Frequentist methods are so named because they attempt to estimate effect sizes imagining a study or test were repeated 10s, 100s, or 1000s of times. Team Frequentist Methods attempt to compare the observed distribution of data with the expected distribution of data assuming the null hypothesis was true. Let’s say we flipped a coin 100 times and counted how many times we got heads. Then let’s pretend we did that same experiment 1000 times. If the coin was fair, your distribution of heads would look something like this:
Frequentist methods are so named because they attempt to estimate effect sizes imagining a study or test were repeated 10s, 100s, or 1000s of times. Team Frequentist Methods attempt to compare the observed distribution of data with the expected distribution of data assuming the null hypothesis was true. Let’s say we flipped a coin 100 times and counted how many times we got heads. Then let’s pretend we did that same experiment 1000 times. If the coin was fair, your distribution of heads would look something like this:

Most of the time, you get a number around 50. Not every time, of course. But the farther you move away from 50 the less likely you are to achieve these results, assuming the coin is fair.
Now, if I wanted to determine if a coin were fair, I could flip it 100 times and count how many times I got heads. Frequentist statistics allow us to quantify just how unlikely my outcome is, knowing what we know about how fair coins behave.
If I got 55 heads (p=0.37), I might not be too surprised. If I got 60 (p=0.06), I might begin to suspect that something was fishy about this coin. If it came up heads 90 times (p<0.000001), well, I’d be pretty convinced that this was not a fair coin.
Frequentist Methods give us information about the likelihood of our result assuming that the effect we’re looking for isn’t there. It gives us comfort to reject the null hypothesis. What more could you ask for from a statistical method? I want to know whether my drug works, you tell me the chance that it doesn’t work.
This is where Bayesian Methods walk in and slap you across the face. Did I really just write that p-values give us the probability that the drug doesn’t actually work? Sacrilege. A p-value merely describes the chance of seeing the results we got (or more extreme) if the drug didn’t work. It’s the probability of our data given the null hypothesis, NOT the probability of the null hypothesis given the data.
Frequentist Methods have been hiding behind this misunderstanding for too long, and many odds-makers think its Bayesian Methods who can call them out on their shenanigans.
Pragmatic Trials vs Adaptive Clinical Trials
Our second matchup pits two new kids on the block in a head-to-head for the future of randomized clinical trial design. Who will emerge to claim all those NIH grants and industry funding?
Pragmatic Trials
 Clinical trials where patients are exquisitely vetted against 100s of inclusion and exclusion criteria, then rigorously followed by a carefully developed protocol are so passé. Pragmatic trials do away with all those efforts to figure out how something works, and just asks the question:
Clinical trials where patients are exquisitely vetted against 100s of inclusion and exclusion criteria, then rigorously followed by a carefully developed protocol are so passé. Pragmatic trials do away with all those efforts to figure out how something works, and just asks the question:
Does it actually work?
Team Pragmatic Trials aim to recapitulate the real world as much as possible. In contrast with more traditional clinical trial design, pragmatic trials enroll broadly with simple, easy-to-manage exclusion criteria. And instead of following patients with monthly visits and blood tests and what not, a pragmatic trial will typically use some highly relevant outcome that is pretty easy to measure, like death. There is rarely blinding—after all, when we really treat a patient, do we blind them to what we are giving them? In this sense pragmatic trials trade internal validity for generalizability, and give us a sense of effectiveness, as opposed to efficacy.
There’s an ongoing pragmatic trial in nephrology that seeks to answer a clinical question faced at least 3 times a week: How much time should I put my patient on dialysis?
This trial randomizes 320 dialysis units to usual care versus a 4.25hr minimum session duration. Simple, right? No fancy inclusion/exclusion criteria, no continuously monitored biomarkers. Just long dialysis versus usual dialysis and after a year or so, tally up what happened to the patients.
While it may seem a bit far away from the rigid experimental design we’ve come to expect, it offers a certain appeal. A positive experimental randomized trial often leaves you wondering—yes, but will this help MY patients? A positive pragmatic clinical trial tells you—yes it probably will, we’re just not sure how.
Boosting the stats for Team Pragmatic Trials is a major push from both PCORI and the NIH to do more of these things. They’re big, they’re clinically meaningful, they impact care. A tough contest indeed.
Adaptive Trials
 Are the days of 1:1 randomization gone? Not yet, but they might get moved to the subacute nursing facility if team Adaptive Trials have their way. Adaptive Trials use information gained from earlier patients in the trial to change the study as it is going on. The cool technique was pioneered, like so many awesome things, in the oncology literature, and brings a new ethical twist to old-fashioned experimentation.
Are the days of 1:1 randomization gone? Not yet, but they might get moved to the subacute nursing facility if team Adaptive Trials have their way. Adaptive Trials use information gained from earlier patients in the trial to change the study as it is going on. The cool technique was pioneered, like so many awesome things, in the oncology literature, and brings a new ethical twist to old-fashioned experimentation.
The idea goes like this. Let’s say you have a drug that might work for some advanced type of cancer. You start your clinical trial randomizing people 1:1 to get drug or placebo, just like always. But as the trial goes on, you allow yourself to bias the randomization towards the drug arm if it looks like the drug actually works. You expose less people to the placebo group and given more people a chance to benefit from this novel therapy.
Sound like a win-win? Well, changing your study design in the middle of the road comes with certain costs. For one, by biasing enrollment, you actually end up needing to enroll MORE people to achieve that statistically significant difference. Granted, you’ll enroll less people in the placebo arm, but you’ll still expose more people to the risks of being in a trial in the first place.
What’s more, every time you check in on your data to see how you should bias enrollment, you run the risk of seeing a significant p-value that will force you to stop the trial. The more times you do this, the more likely you are to stop the trial early, and the more likely you are to have made a type 1 (false positive) error. Those in the know refer to “spending p” when they do these interim checks. Every time you do it, you need to make your statistical significance criteria more strict (which is why you’ll see some of these studies defining statistical significance at a threshold of 0.047 or something strange like that).
Adaptive trials have yet to make their way into the nephrology zeitgeist, but our oncology colleagues have them in spades. The “I-Spy 2” trial for women with breast cancer, randomizes individuals to standard care (neoadjuvant chemo) versus standard care plus an investigational drug. The twist? They don’t know what the investigational drug might be. Rather, they look at your tumor biomarkers, examine patients who have been in the trial earlier, and pick an agent that looks like it might work for you. The hope is that by the end of the trial they have multiple targeted and personalized therapies for breast cancer. Pretty cool.
Adaptive designs are metastasizing—cropping up in diverse areas of the medical landscape. And they aren’t limited to simply biasing randomization. You can design an adaptive trial to figure out what dose to give people, or what subgroups to continue enrolling. It’s a dynamic world out there, shouldn’t our clinical trials be dynamic too?
– Post written and edited by Dr. Perry Wilson and Matt Sparks.
![]()
Leave a Reply